Workshop Overview
Date and Location
Karlsruhe: 09.06.2022 - 10.06.2022
Participants (Alphabetically)
Mr. Adam Basha, Prof. Albena Lederer, Mr. Alexander Grimm, Prof. Bradley Olsen, Prof. Christine Luscombe, Prof. Christoph Steinbeck, Dr. Christopher Klein, Ms. Claire Lin, Mr. Daniel Döpping, Dr. Dominik Voll, Mr. Jonas Eichhorn, Ms. Leah McEwen, Mr. Lukas Siegwardt, Prof. Martina Stenzel, Ms. Melina Feldhof, Dr. Michael Deagen, Prof. Michael Meier, Ms. Michele Illmann, Dr. Nezha Badi, Dr. Nicole Jung, Ms. Noura Rayya, Prof. Patrick Theato, Ms. Pei-Chi Huang, Dr. Steffen Neumann, Dr. Susanne Boye, Ms. Tasnim Mehzabin, Dr. Valerian Hirschberg.
Introduction
Data Life Cycle
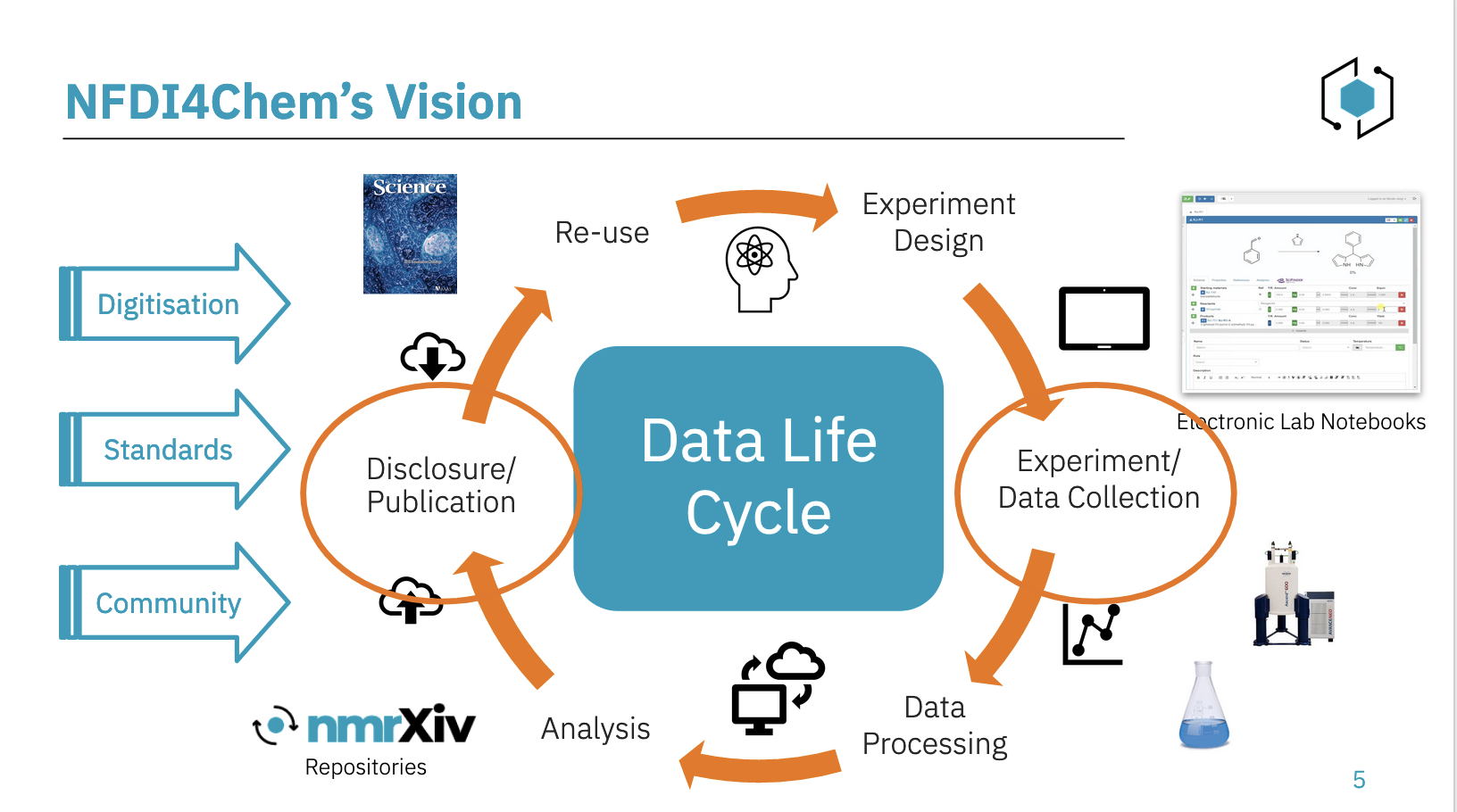 In this cycle, the Electronic Lab Notebook (ELN) role comes mainly in the Experiment/Data Collection step, where acquisition and documentation can happen, while repositories facilitate the data Disclosure and Publication. Those repositories include RADAR4Chem, which is a generic repository where we have the flexibility, but we miss the structure needed. Another repository is Chemotion. Both are open to all countries.
In this cycle, the Electronic Lab Notebook (ELN) role comes mainly in the Experiment/Data Collection step, where acquisition and documentation can happen, while repositories facilitate the data Disclosure and Publication. Those repositories include RADAR4Chem, which is a generic repository where we have the flexibility, but we miss the structure needed. Another repository is Chemotion. Both are open to all countries.
NFDI4Chem Support for Data Publication
- Lead-by-example: We would like to collect datasets that are as complete as possible today using the tools developed in NFDI4Chem.
- NFDI4Chem helpdesk: It provide consulting on how to structure the data.
- NFDI4Chem workshop series on RDM (Research Data Management): We provide talks and receive questions. Registration is open, and we have many events coming. The workshops (online) are open to all people, and internationalization is part of our mission.
The Minimum Information on Chemistry Investigations (MIChI)
Data needs to be associated with metadata, otherwise, data loses context. Metadata can be domain independent (funder, publisher, author, dates..) or specific, as in the domain of chemistry. We are especially interested in the Minimum Information subset out of the metadata, which we call minimum information on Chemistry investigation (MIChI). We can store the MIChI standards on specific repositories like FAIRsharing.
We would like to provide our MIChI as:
- Guidelines article: Useful for students and researchers.
- Checklist for authors
- Data Model: A conceptual idea for the programmers.
- Ontology terms: to support the MIChI.
- Implementation can happen in ELNs and repositories, and behind the scene, you have the APIs, databases, and the file formats.
Structured data can be tedious work, but it saves a lot of time later when we need to publish, it is also essential for reusability
Publication with Chemotion
Using Chemotion ELN or repository, one can generate reports that contain the description, the reaction scheme, identifiers and information coming from the identifiers (such as the molecular mass). If the data comes from the repository, the report contains its DOI. Supplemental information then can be submitted to the journals. If the data is already published in journals, corresponding links can be added to the “Reference” section.
Supplemental information is already partially standardized for organic chemistry but not completely, as standardized elements such as the names and identifiers are being used in larger non-standardized sections, such as the description and results.
Introduction in Polymer Chemistry
Polymer 101
A macromolecule is the single chain while the polymer is an ensemble of macromolecules (multiple macromolecular chains), this is challenging as we need to look into both the macromolecule and the polymer. Additionally, polymers have distributions in their chain length, the broadness of distribution depends on the synthetic way and we don’t have those issues in the macromolecule. However, the information on the macromolecule level and the polymer level go hand in hand.
One can synthesize aspirin by many methods, paths, and people, and the same material will always be obtained. But in the case of polymers, one will get another polymer each time, as the resulting polymers might have similar properties, but they still differ on the molecular level. This is why we are always dealing with statistical distribution when dealing with polymers.
Naming Polymers
It is challenging as different principles are followed.
- Source based naming: Starting from the monomer and adding poly in front of it. It is an easy way, but it doesn’t always work and it is not always correct.
- IUPAC, based on constitutional repeating units: IUPAC naming works only for simple polymers, but then it becomes very long.
- Abbreviations and acronyms: They can be not clear for non polymer chemists.
- Trade names are useful for narrow fields.
- There are also rules for SMILES and big SMILES that are not much easy to use regularly.
From Small Molecules to Polymers - Challenges with Digitalization
- Small molecules can be analyzed by relatively simple methods, such as NMR, IR, and MS, but when they form a polymer or an oligomer, they need more difficult and specialized methods, such as SEC, MALDI-ToF, SEC/ESI MS.
- The repeating units in the product polymer can be controlled during the reaction, but such details are difficult to mirror in ELNs (such as Chemotion ELN). The same happens with nested polymers structures, which are very common.
- The materials generated from polymers can undergo further procedures (post modifications) that are difficult to include in ELNs.
- When it comes to polymers, we have neither standardized names, reaction information, sample structures, nor repositories entries with identifiers.
Polymers Minimum Information
Many MI are actually expanding to become "Maximum" standards and they are really extensive. This problem can be tackled by having several levels of mandations, e.i., mandatory, recommened, and optional. The ELN might be a great first data-entry spot where these levels can be tranlsated into flags. ELNs can also serve by collecting statistics on how people report their data, where all input fields can start as optional, and based on a certain suggested percentage of users reporting this data, it can become recommended or later mandatory. There remains the risk of people report random data when Forced to fill in the mandatory fields which they don't have.
One point to keep in mind about MI is its dependency on the field, e.g., for battery science you might only care about ion connectivity where molecular weight might not be of concern. This can easily be noticed in the different journals.
Polymers Description - On The Way to MIChI
There is some basic information that can be used to describe polymers and the procedures carried out to generate them. In the following table you can find a basic description of a polymer.
| Information | Details |
|---|---|
| Synthesis | method, yield, degree of polymerization |
| Chemical identity | Which polymer is this? What additives are present? Is there contamination? |
| Morphology | Amount of crystallinity (tacticity?), optical properties |
| Molecular weight | Mn, Mw, etc. : Molecular weight distribution Ð = Mw/Mn |
| Solution behavior | Viscosity, flow, gel |
| Solution behavior | Viscosity, flow, gel |
| Thermal behavior | Glass transition, melt and decomposition temperature, melt viscosity |
| Mechanical properties | Tensile strength, modulus, impact, creep, dimensional stability |
And next you can find a basic description of a polymer generation process with its expected metadata. Most important ones are highlighted.
| Step | Sub-steps |
|---|---|
| Humans |
|
| Planning |
|
| Synthesis |
|
| Analytics |
|
| Processing Application |
|
Polymers in Electronic Structure Editors
There are several available electronic structure editors that can handle polymers and, from which, Chemotion ELN users can pick, including:
- Ketcher
- Marvin
- ChemDraw
- HELM
ChemDraw
- Most people in the workshop only use Chemdraw, but:
- It provides a wide span of functions which polymer chemists don’t actually use.
- It needs more documentation.
- It is not possible to define []x-y.
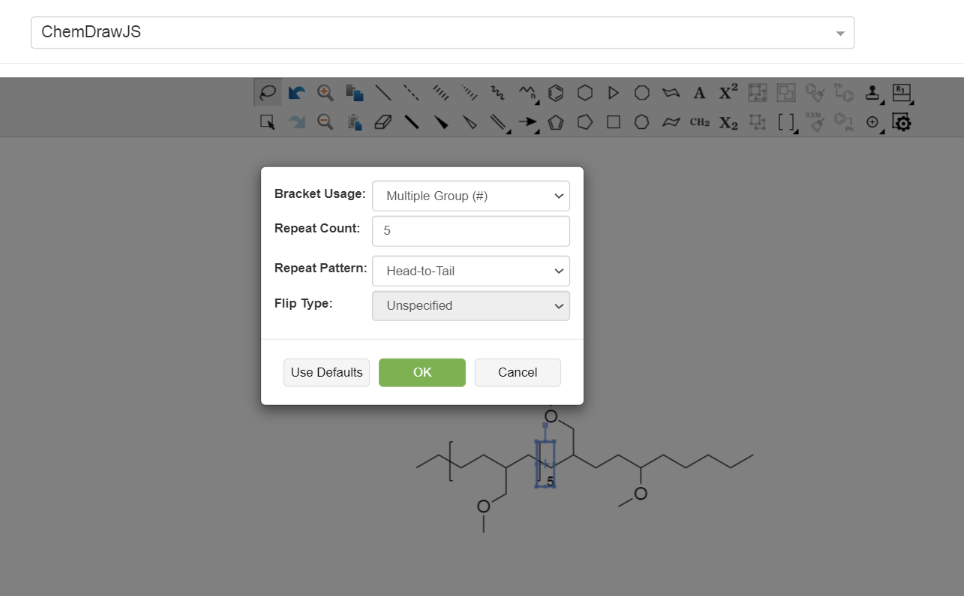
Polymers in Electronic Lab Notebooks
On top of what the editors provide, ELNs can describe procceses as planned, ongoing, succeeded, failed. This becomes handy remembering the importance of maintaining failure results, which people might not be interested in publishing at the beginning, but these results are very important on their own to show others what actually works, and also for machine learning as better training comes with a mixed of good and bad data. This is still challenging when it comes to publications as reviewers might not be interested, and such results are usually not provided in the supporting material. We need to record what the polymer community finds useful and we can work on it day to day.
Furthermore, ELNs help in keeping notes on why you picked a certain parameter, e.g. why an experiment is done at a certain temperature, along with the random variables not thought of by the researcher, which they might miss recording.
When it comes to MI, ELNs can prevent the scenario of needing to report a certain mandatory parameter, but failing to do so as it wasn't recorded during the experiment. But more discussion is needed for MIs in ELNs, for instance, in addition to showing and describing the polymer, we still need to provide the dataset, the repeating units, and how they are linked because it is something you can’t show in chemdraw and you need to describe in words, along with the application in mind, on which the polymer charectrisitcs depend, and the analysis method by which the molecular weight was obtained.
With rubbers, which are polymers that can be natural or synthesized, the crosslinked materials and networks should be distinguished from other materials, but most cross linking is not well defined and sometimes it is not possible (Challenge to define Cross linked materials), which makes crosslinking very complicated for data management. With cross linked sample, we have one macromolecule and it is the same as the polymer.
Although peptides can be presented as a biological molecule that shares properties with non biological polymers, they have completely different properties as points of interest and it is better to keep thinking of the user while defining entities, this is why proteins and peptides are not part of our concern here. What about polymer and protein combination products? And what about polymers that are proteins and what about polysaccharides? Should we keep the details section as it is or should we add more options?
Reactions and Processes in Polymer Chemistry
You can make the same polymer by different polymerization methods, but those methods affect the molar mass distribution . Chain growth method leads to narrow distribution while step growth one leads to wider distribution. Molecular mass distribution: there could be a distribution of the polymer or for each chain, which affects the calculated dispersity. Additionally, higher molecular weight might not be soluble and this affects the measurements. Thermal properties: for semicrystalline polymers there are more data than the amorphous ones. And they need to be reported. Polymer can be generated from one of two different monomers with one of two different methods but it will have different properties such as the distribution.
Degradation and recycling of polymers will be important going forward. Extrusion, coating etc. are still “processes” but not chemical reactions and might still be relevant for some people. Contamination needs to be clarified: Copper contamination details are usually not mentioned although they affect the analyses.
Dropdowns may result in data loss, we need to be able to note/share reasons behind failed experiments (share knowledge within research groups) and also to provide whatever helpful info, data, photos, e.g., how to set up instrument. Temperature is very important too, one reaction might work in one season and not the other.
Our recommended checklist can be a part of a knowledge base and not necessarily provided in Chemotion, but it can be available as a link in chemotion as a bare suggestion and inspiration. A popup may appear which may link to the checklist. The reactions are the only process in the ELN, but we need to reach out to material scientists to see what other processes needed other than classic reactions (option to have non classical chem. Reactions in ELN).
In a controlled vocabulary, we can pick the leaves of the tree as actual procedures, while at top are the classifications.
As only chemical reactions are allowed in ELN, we may start with a molecular structure/starting material however the product becomes undefined after reaction. We can have the process defined by the starting material and the conditions, the question would be what calculations are needed? Is it better to provide a detailed definition for the equipment? Some details can be very specific, such as the volume flask type, it is useful to provide the possibility for the user to add it, so it works as a reminder. The flask type can be very important and affect the result where the polymer is not generated as desired. But maybe this needs to be added in a free text as it is difficult to suggest all types of equipment. Suggestion: Add photos of instrumentation setups.
Analyses in Polymer Chemistry
The importance of different techniques varies based on the field, we can’t always say that one technique is rarely used. Analysis setups depends on the reaction type. We can have a checklist of measurements as reviewers, we check if they are applicable, and if so, were any of them provided. We shouldn’t force people to enter data (but include option as not applicable might guide researchers to enter data, which serves goal of FAIR data).
The most important analysis for polymer chemistry is SEC, so we should include SEC measurements in Chemotion ELN
Selected Analyses Types
With the large complexity of the field, we have to decide which experiments we need to do as complex systems cannot be defined with a few parameters. For that raw data is needed to analyze it later, It should be saved directly to restructure it afterwards. For the standard we need processing, defining test and test conditions.
Rheology measures the properties.Its subclasses including shear rheometry and temperature-dependent rheometry are not needed in the ELN as temperature should always be specified and the system is able to collect and provide all the metadata (the parameters). The rheological analysis results sould be included directly in the polymer rather than in its analysis. We can extract data depending on the type of viscosity measurement (viscosity definition depends on the type of measurement). We repeat the measurements in rheologica at least 10 (challenge). All experiments need repetition. Normally 10 repetitions are suggested. Depends on the experiments also to determine how many repetitions are needed
Shear rheometry and temperature-dependent rheometry are used to classify the experiments depending on the properties like temperature and what kind of mechanical variety we applied for this. In their doscumentation, we will need to get and show how molecular weight was defined.
The data file for this measurement is less than megabyte as a spreadsheet, but when we have images we add much additional size. The file is excel sheets with large storage capacity. The raw data is a text file with almost 10 kilo, if you keep the graph the size remains small. We should be able to pick one point from the graph and show it in the ELN. Everything should start as raw data and then we should select a template to analyze the data.
Frequency, amplitude, temperature are three important parameters, we also need the topology of the polymer and the analysis model. in the subdivision, we should put the analysis model data, which depends on the number of parameters.
Sample preparation details are needed, for example, is there water? The preparation mechanical and it includes high heating and high pressure and so.
Minimum Information Determination for Rheology
Type of experiment: It is more important than the machine as it defines the machine, how to prepare the sample, then one decides the more specialized parameters. Density and viscosity are the basic parameters. The Tab Advanced rheological properties can be modified.
Selected Analyses in Polymer Chemistry
SEC is relatively easy, while the needed techniques for absolute mass can be expensive. First bigger molecules will elude and then the smaller ones. For ELN, in addition to the slides, we need
- Temperature
- The number of the columns For Absolute: specify if the dn/dc is determined by the user or from vendor
Device Integration Demo
There are at least 3 strategies for device integration into the ELN according to workflow. The API is necessary for that. The devices store the data centrally and the ELN pulls the data to its server. This is also working for NMR, MS, IR, Raman, and the workflow is independent from the method but the further processing isn’t. The converter is still being worked on. This is much better than working with screen-shots as they are not machine readable. Transfer occurs either directly by email, automatic transfer to central data storage or manual transfer. The transferred data goes to the inbox that is arranged in folders For SEC, the workflow is already established. If samples are sent to another institute the results will be displayed in their ELN. Sample naming is important for correct suggestion of data transferred to be assigned to the sample. The analysis tab is displayed in the sample, and the dataset is displayed in the analysis tab. The analyses are now done by chemspectra and it will be combined by NMRium soon as it is specific to NMR and has additional functions for NMR. Device integration is particularly useful as much of the metadata is already provided by the instrument and we don’t need to enter the data manually. With polymer NMR we get low broad peaks that are difficult to interpret even by people. Peaks deletion is possible. There is flexibility in using the ELN as the user can do their results processing using their preferred tools or using the ELN tools.
Sample Analysis Demo
The technique is based on the ontology term we pick resulting in showing a corresponding template with the metadata associated with this technique. The measurement files can be dragged and dropped or they come directly from the device. The ELN provides the maximum metadata needed but the MI still needs to be decided. Currently the metadata provided in the dataset is not connected to the sample (fields not mirrored). Dealing with high number of repeating units without crushing is something we are still working on this in the ELN. Ketcher2 does not support repetition over 1000. However, Marvin supports if there are more than 10000 units. A play around would be to add in Chemdraw and then import in other editor like Marvin. However the calculation of molecular weight still does not take the repeating units into consideration
Available General Guidelines
- Most journals do not have any guidelines in detail for polymer chemistry.
- IUPAC project on polymer, they are working on a brief guide on polymer characterization, a good point to work on.
Data Availability - Now and Desired
When choosing a repository, one should be specific unless no corresponding repository exists, then pick a generic one, So the type of data decides the repository to choose. RADAR4Chem to be used as a generic repository when dataset does not correspond to any disciplinary repository. RADAR4Chem has 10GB space to store the data. We need to resolve the storage limitation by fund providers, not the scientists
Chemotion Repository Demo
While open for everyone, signing in gives you a better view. Human curation is there as the data submitted is still limited.
Final Suggestions:
Polymer MIChI
- Polymer structure
- the repeating units
- how they are linked (described in words)
- head-to-head
- head-to-tail
- Tail-to-tail
- n, m, … - definition
- Analytics:
- The molecular weight
- Dataset
- The application in mind
Future Discussions
-
What is the Minimum Information in polymer synthesis?
-
What is the Minimum Information in structural characterization?
-
What is the Minimum Information in property characterization?
-
What is the most suitable structure editor for polymers tool?
-
Can all editors mentioned in this overview be used adequately?
-
What definitions are necessary in ELN/for documentation?
-
Are polymers with different numbers of repeating units (Polymer with []10 and []5) different molecules?
-
Is the number of repeating units (e.g.,n) defined in every case, or some of them?
-
where to define n,m,o? in ELN masks?
-
Is the assignment to one molecule for undefined n and m correct? When should this definition be used? Do we want to use n and m for calculations or are they just placeholders?
-
Is []n, []m the same molecule as []n, []5?
-
Do polymers with []10 and []n belong to the same molecule as []10?
-
Will scientists use n,m,o etc and define n,m,o then in the details? In consequence, polymer samples with different molecular weights will belong to the same molecule?
-
How to deal with polymers with n = range? The editors currently are not giving the right calculation of the mass. This is because the values provided are usually representing the mean, not the real value that actually belongs to a range.
-
For which information is important how it was gained? → instruments, conditions?
-
Should we keep asking about the polymer type? Classification can be based on the polymer being soluble or not (Microgel as a subclass for instance). Most importantly: more work on defining subclasses.
-
Are the types enough or should we extend them?
- Homopolymers and copolymers are good, but the others are too specific (e.g.,: microgel might not be necessary a substructure). Microgel maybe could be included in a wider class like fiber.
- Rubbers are polymers that can be natural or synthesized, and the crosslinked materials, and networks should be distinguished from other materials, but most cross linking is not well defined and sometimes it is not possible (Challenge to define Cross linked materials), which makes crosslinking very complicated for data management.
- With cross linked sample, we have one macromolecule and it is the same as the polymer.
-
Graph polymer: what is the best way to include it in the synthesize way (in Chemotion)? Should there be one part or they should be divided?
-
Is it better to provide a detailed definition for the equipment?
Next:
- Polymer identity
- Standardized naming
- Check what the vendor provides to characterize the bought polymer
- ELN:
- Integrate polymer analytical methods
- Polymer procedures:
- Standardized reaction description
- Post modifications procedures description
- Addition of a “polymerization” tab to the reaction element.
- Methods to be provided from an ontology
- Reach out to material scientists to see what other processes needed other than classic reactions (option to have non classical chem. Reactions in ELN).
- Calculate the number/range of repeating Units
- Defining the repeating units
- Giving the molecular mass from e.g., SEC
- Maybe only feasible for homopolymers
- Polymers are sorted together will change with PolymerInChi.
- Collect comments on the template
- Improve Microgel definition
- Provide the analytical method along with the molecular weight.
- Calculate The degree of polymerization from the available fields.
- Additional fields for narrow distribution and for the dispersity might be needed. It can be automatically decided based on defined values available.
- Add temperature.
- Collect screenshots of LAbarchive template from the participants.
- We need examples of instruments and the raw data file in the vendor format and the export csv.
- Chemotion repository:
- Can it help with providing identifiers for polymers? As they are samples not reference compounds?
- MI:
- Synthesis
- Structural Characterization
- Property Characterization
- Consider Polydat approach
- Contact journal editors in the field as they can provide suggestions for the checklist (RSC Polymer Chemistry)
- IUPAC project on polymer, they are working on a brief guide on polymer characterization, a good point to work on.